理論グループのミーティングの報告
日時:97/05/20
場所:齋藤理一郎 助教授 西5-517
メモリ,GL,GSの配置と ハウスホルダー変換の手順について
- ○今回の変更点は、GL のメモリの データバスを 独立にした。
-
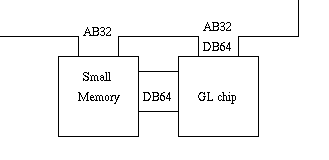
- この様な構成にすると GL を通過して GS に 入力される場合についでに演算を加えることが出来る。
- ○ハウスホルダー変換の手順を示した。
- Wk Ck αk βk を求める。
- Pk を 求める
- qk を求める
- Ak+1 を求める
- チップ間の通信 がおおいのは Ak+1 の計算で
4 N2 /NGS cycle、
次に多いのが Pk+1 を求めるもので
N2 /NGS cycle
- 全ての k について の通信 は 約 5 N3/(3 NGS) cycle となる。
- ○上の説明のファイル読んでも わかるのは書いた人だけなので、データのフローを図に示す。
- データのフローの簡略図
- ○データ量と演算量と計算速度 の関係
- ハウスホルダー変換に必要な 計算は データ量 N に対して N^3 に比例した演算が必要といわれる。計算速度をあげるには、演算速度をあげるか、演算器の数を増やすことになる。演算器の速度は、そんなに自由にならないが、数の方は比較的自由である。ここでどのように メモリと演算器を構成すれば良いかを考えることになる。
- ハウスホルダー変換に必要な計算はベクトルの内積とか、引き算がほとんどであるが、それ(内積・引き算)を速くするために、演算器の数を増やしても、通信速度が律速になってしまう。なぜなら、データ数/2 と 演算回数 の 比は 1 : 1 程度であるから、演算器にデータを配る時間がそのまま、計算速度になってしまう。
- 計算速度を速くするには、同時に演算器にデータを送らなくてはならない。チップ のなかにすっぽり データが存在できれば、それは可能であるが、いまのところ実現不可能。
- ハウスホルダー変換は、ベクトルにわけて、それぞれ 別々に内積や引き算してもかまわないので、それぞれのベクトル計算を 並列に計算出来るので、そこに注目して、演算器を増やしたのが
今回の、Ver.2 の構成である。
(注: グェン君風邪で欠席)
戻る